
Introduction
Souvent, lorsque nous voulons résoudre un problème de PNL, nous utilisons des modèles de langage pré-entraînés, en prenant évidemment soin de choisir le modèle le plus approprié et affiné sur le langage qui nous intéresse.
Par exemple, si je travaille sur un projet basé sur la langue italienne, j’utiliserai des modèles tels que dbmdz/bert-base-italian-xxl-cased ou dbmdz/bert-base-italian-xxl-uncased .
Ces modèles de langage fonctionnent généralement très bien sur du texte générique, mais ne s’adaptent souvent pas bien lorsque nous les utilisons dans un domaine spécifique , par exemple si nous les utilisons dans un domaine médical ou scientifique qui a son langage particulier .
Pour cela, nous devons appliquer l’adaptation de domaine !
L’adaptation de domaine, c’est lorsque nous affinons un modèle pré-entraîné sur un nouvel ensemble de données, et cela donne des prédictions plus adaptées à cet ensemble de données.
Que signifie le réglage fin ?
Le réglage fin en PNL fait référence à la procédure de recyclage d’un modèle de langage pré-entraîné à l’aide de vos propres données personnalisées . À la suite de la procédure de réglage fin, les poids du modèle d’origine sont mis à jour pour tenir compte des caractéristiques des données du domaine et de la tâche qui vous intéresse.
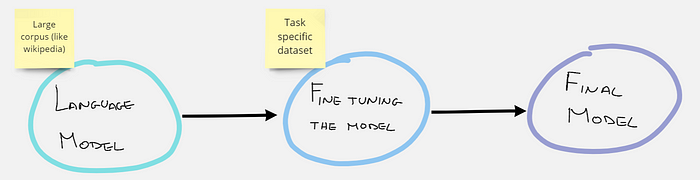
Dans notre cas, nous affinerons à l’aide d’un tâche de modèle de langage masqué (MLM). En d’autres termes, notre ensemble de données n’aura pas d’étiquettes préfixées, mais pour chaque phrase certains mots seront cachés (masqués), et le modèle devra deviner quels sont les mots cachés.
Base de données
La base de données que nous allons utiliser à cette fin est publique et peut être trouvée sur Kaggle à ce lien . Cet ensemble de données contient environ 13 000 actualités . Nous ne nous intéressons qu’au contenu de l’avis, il vous suffit donc d’utiliser la colonne de texte . Dans cet article je ne décrirai pas la procédure pour télécharger l’ensemble de données depuis kaggle et extraire le fichier csv, en cas de problème vous pouvez lire les autres articles que j’ai postés sur TDS.
Pratique
Importons d’abord toutes les bibliothèques dont nous aurons besoin.
!pip install -q transformers
!pip install -q datasets
import multiprocessing
import pandas as pd
import numpy as np
import torch
import matplotlib.pyplot as plt
import transformers
from sklearn.model_selection import train_test_split
from datasets import Dataset
from transformers import AutoModelForMaskedLM
from transformers import AutoTokenizer, AutoConfig
from transformers import BertForMaskedLM, DistilBertForMaskedLM
from transformers import BertTokenizer, DistilBertTokenizer
from transformers import RobertaTokenizer, RobertaForMaskedLM
from transformers import Trainer, TrainingArguments
from transformers import DataCollatorForLanguageModeling
from tokenizers import BertWordPieceTokenizerDéfinissons les hyperparamètres nécessaires à la formation du modèle. (N’hésitez pas à jouer avec eux si vous disposez de suffisamment de puissance de calcul !)
# HYPERPARAMS
SEED_SPLIT = 0
SEED_TRAIN = 0
MAX_SEQ_LEN = 128
TRAIN_BATCH_SIZE = 16
EVAL_BATCH_SIZE = 16
LEARNING_RATE = 2e-5
LR_WARMUP_STEPS = 100
WEIGHT_DECAY = 0.01Commençons par la préparation des données. Chargez votre fichier csv, divisez-le et transformez-le en objet Dataset.
# load data
dtf_mlm = pd.read_csv('news-adaptive-tuning_dataset.csv')
#dtf_mlm = dtf_mlm.rename(columns={"review_content": "text"})
# Train/Valid Split
df_train, df_valid = train_test_split(
dtf_mlm, test_size=0.15, random_state=SEED_SPLIT
)
len(df_train), len(df_valid)
# Convert to Dataset object
train_dataset = Dataset.from_pandas(df_train[['text']].dropna())
valid_dataset = Dataset.from_pandas(df_valid[['text']].dropna())Préparation des données
Vous devez maintenant choisir votre modèle de stratégie et votre tokenizer. J’aime utiliser Distilbert car il est léger et plus rapide à entraîner.
'''
bert-base-uncased # 12-layer, 768-hidden, 12-heads, 109M parameters
distilbert-base-uncased # 6-layer, 768-hidden, 12-heads, 65M parameters
'''
MODEL = 'bert'
bert_type = 'bert-base-cased'
if MODEL == 'distilbert':
TokenizerClass = DistilBertTokenizer
ModelClass = DistilBertForMaskedLM
elif MODEL == 'bert':
TokenizerClass = BertTokenizer
ModelClass = BertForMaskedLM
elif MODEL == 'roberta':
TokenizerClass = RobertaTokenizer
ModelClass = RobertaForMaskedLM
elif MODEL == 'scibert':
TokenizerClass = AutoTokenizer
ModelClass = AutoModelForMaskedLM
tokenizer = TokenizerClass.from_pretrained(
bert_type, use_fast=True, do_lower_case=False, max_len=MAX_SEQ_LEN
)
model = ModelClass.from_pretrained(bert_type)Modèle de départ et tokenizer
Afin d’alimenter le modèle, nous devons tokeniser notre ensemble de données.
def tokenize_function(row):
return tokenizer(
row['text'],
padding='max_length',
truncation=True,
max_length=MAX_SEQ_LEN,
return_special_tokens_mask=True)
column_names = train_dataset.column_names
train_dataset = train_dataset.map(
tokenize_function,
batched=True,
num_proc=multiprocessing.cpu_count(),
remove_columns=column_names,
)
valid_dataset = valid_dataset.map(
tokenize_function,
batched=True,
num_proc=multiprocessing.cpu_count(),
remove_columns=column_names,
)Nous pouvons maintenant réellement entraîner notre modèle. Le DataCollatorForLanguageModeling est une fonction qui nous permet d’entraîner très facilement le modèle sur une tâche de langage masqué.
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=0.15
)
steps_per_epoch = int(len(train_dataset) / TRAIN_BATCH_SIZE)
training_args = TrainingArguments(
output_dir='./bert-news',
logging_dir='./LMlogs',
num_train_epochs=2,
do_train=True,
do_eval=True,
per_device_train_batch_size=TRAIN_BATCH_SIZE,
per_device_eval_batch_size=EVAL_BATCH_SIZE,
warmup_steps=LR_WARMUP_STEPS,
save_steps=steps_per_epoch,
save_total_limit=3,
weight_decay=WEIGHT_DECAY,
learning_rate=LEARNING_RATE,
evaluation_strategy='epoch',
save_strategy='epoch',
load_best_model_at_end=True,
metric_for_best_model='loss',
greater_is_better=False,
seed=SEED_TRAIN
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model("your_path/model") #save your custom modelEntraînez et enregistrez votre modèle personnalisé
Évaluation de la perplexité
Le modèle personnalisé que vous avez créé est-il vraiment meilleur que le modèle source ? Pour comprendre s’il y a eu des améliorations on peut calculer la perplexité du modèle ! Si cette métrique vous intéresse, lisez cet article .
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased', use_fast = False, do_lower_case=True)
model = AutoModelForMaskedLM.from_pretrained('bert-base-uncased')
trainer = Trainer(
model=model,
data_collator=data_collator,a
#train_dataset=tokenized_dataset_2['train'],
eval_dataset=valid_dataset,
tokenizer=tokenizer,
)
eval_results = trainer.evaluate()
print('Evaluation results: ', eval_results)
print(f"Perplexity: {math.exp(eval_results['eval_loss']):.3f}")
print('----------------\n')Perplexité du modèle original
import glob
import math
path = "your_path/model"
for modelpath in glob.iglob(path):
print('Model: ', modelpath)
tokenizer = AutoTokenizer.from_pretrained(modelpath, use_fast = False, do_lower_case=True)
model = AutoModelForMaskedLM.from_pretrained(modelpath)
trainer = Trainer(
model=model,
data_collator=data_collator,
#train_dataset=tokenized_dataset_2['train'],
eval_dataset=valid_dataset,
tokenizer=tokenizer,
)
eval_results = trainer.evaluate()
print('Evaluation results: ', eval_results)
print(f"Perplexity: {math.exp(eval_results['eval_loss']):.3f}")
print('----------------\n')Perplexité du modèle personnalisé
J’espère que vous avez remarqué une amélioration de la perplexité du modèle !
Publiez votre modèle personnalisé sur Hugging Face !
Si vous avez entraîné votre modèle sur un ensemble de données personnelles ou sur un ensemble de données particulier que vous avez créé vous-même, votre modèle pourrait probablement être utile à quelqu’un d’autre. Téléchargez-le sur votre compte Hugging Face avec seulement quelques lignes de code !
Tout d’abord, créez un compte personnel sur Hugging Face, puis exécutez les commandes suivantes.
!pip install huggingface_hub
#login hugging face
from huggingface_hub import notebook_login
notebook_login()
#push your model
model = DistilBertForMaskedLM.from_pretrained("your_path/model")
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path = "your_path/model")
model.push_to_hub("cool-name-of-your-model")
tokenizer.push_to_hub("cool-name-of-your-model")Téléchargez votre modèle sur le visage câlin
Fait! Votre modèle est désormais sur Hugging Face et tout le monde peut le télécharger et l’utiliser ! Nous vous remercions de votre contribution!

