
Vous avez probablement déjà entendu parler de Kubernetes , un puissant orchestrateur qui facilitera le déploiement et gérera automatiquement vos applications sur un ensemble de machines, appelé Cluster .
Une grande puissance s’accompagne d’une grande complexité, même aux yeux de Google . Ainsi, l’apprentissage de Kubernetes est souvent considéré comme fastidieux et complexe, notamment en raison du nombre de nouveaux concepts à apprendre. D’un autre côté, ces mêmes concepts peuvent être retrouvés chez d’autres orchestrateurs. De ce fait, les maîtriser facilitera votre intégration sur d’autres orchestrateurs, comme Docker Swarm .
Le but de cet article est d’expliquer les concepts les plus utilisés de Kubernetes en s’appuyant sur les concepts de base de l’administration système, puis d’utiliser certains d’entre eux pour déployer un serveur web simple et mettre en valeur les interactions entre les différentes ressources. Enfin, je présenterai les interactions CLI habituelles lorsque je travaille avec Kubernetes.
Cet article se concentre principalement sur le côté développeur d’un cluster Kubernetes, mais je laisserai quelques ressources sur l’administration du cluster à la fin.
Terminologie et concepts
Architecture
Le domaine Kubernetes est le cluster , tout le nécessaire est contenu dans ce cluster. À l’intérieur, vous trouverez deux types de nœuds : le Control Plane et les Worker Nodes .
Le plan de contrôle est un ensemble centralisé de processus qui gère les ressources du cluster, l’équilibre de charge, l’intégrité, etc. Un cluster Kubernetes dispose généralement de plusieurs nœuds de contrôleur à des fins de disponibilité et d’équilibrage de charge.
En tant que développeur, vous interagirez très probablement via la passerelle API pour les interactions.
Le nœud de travail est tout type d’hôte exécutant un agent Kubernetes local Kubelet et un processus de communication Kube-Proxy . Le premier gère les opérations commandées par le plan de contrôle sur le runtime du conteneur local ( par exemple docker), tandis que le second redirige la connectivité vers les bons pods.

Espaces de noms
Après un certain temps, un cluster Kubernetes peut devenir énorme et très utilisé. Afin de garder les choses bien organisées, Kubernetes a créé le concept de Namespace . Un espace de noms est essentiellement un cluster virtuel à l’intérieur du cluster réel.
La plupart des ressources seront contenues dans un espace de noms, ignorant ainsi les ressources d’autres espaces de noms. Seuls quelques types de ressources sont totalement indépendants des espaces de noms et définissent la puissance de calcul ou les sources de stockage ( c’est-à-dire les nœuds et les volumes persistants). Cependant, l’accès à ceux-ci peut être limité par l’espace de noms à l’aide de Quotas .
Les ressources prenant en charge les espaces de noms seront toujours contenues dans un espace de noms car Kubernetes crée et utilise un espace de noms nommé par défaut si rien n’est spécifié.
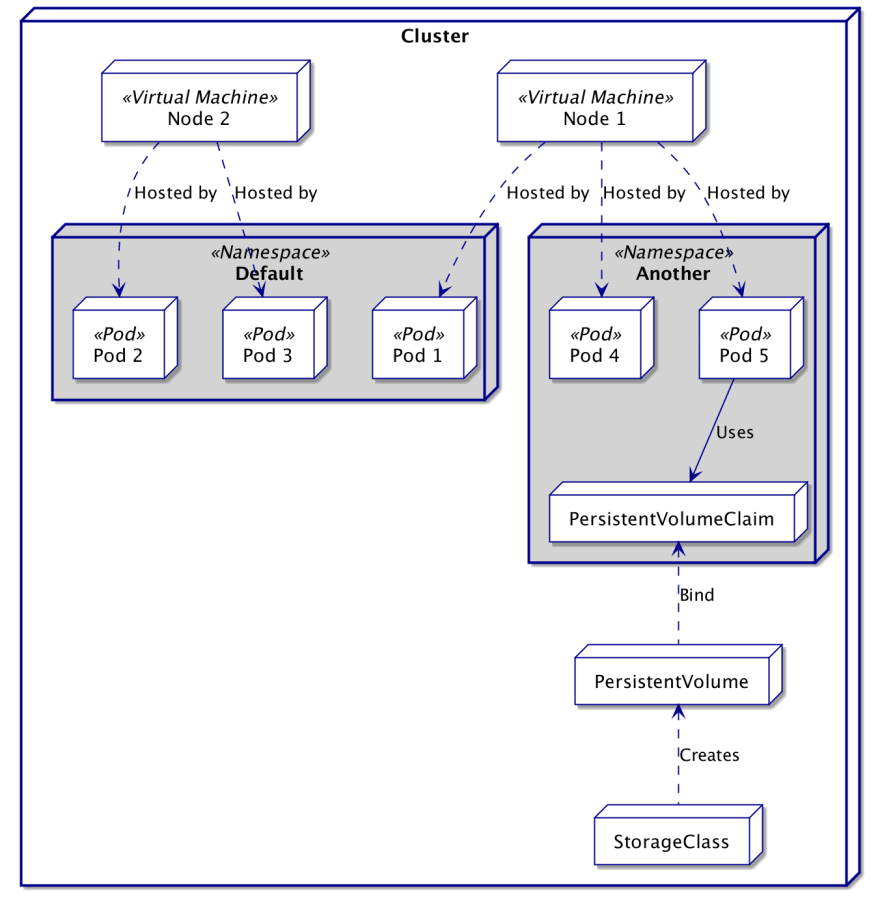
Il n’existe pas de solution miracle quant à la manière d’utiliser les espaces de noms, car cela dépend largement de votre organisation et de vos besoins. Cependant, nous pouvons noter quelques usages habituels des espaces de noms :
- Divisez le cluster par équipe ou projet, pour éviter les conflits de noms et faciliter la répartition des ressources.
- Divisez le cluster par environnement ( c’est-à-dire dev, staging, prod), pour conserver une architecture cohérente.
- Déployez avec plus de granularité ( par exemple déploiement bleu/vert ), pour revenir rapidement sur un environnement de travail intact en cas de problème.
Lectures complémentaires :
Glossaire
Kubernetes a fait un excellent travail en restant indépendant de toute technologie dans sa conception. Cela signifie deux choses : gérer plusieurs technologies sous le capot et il y a une toute nouvelle terminologie à apprendre.
Heureusement, ces concepts sont assez simples et peuvent la plupart du temps être comparés à un élément unitaire d’une infrastructure système classique. Le tableau ci-dessous résumera la liaison des concepts les plus fondamentaux. La comparaison n’est peut-être pas exacte à 100 %, mais elle vise plutôt à aider à comprendre la nécessité derrière chaque concept.
| Couche d’abstraction | Couche physique | Utilise l’espace de noms | Description |
|---|---|---|---|
| Sous | Récipient | ✅ | Un Pod est l’unité de travail minimale de Kubernetes, il équivaut généralement à un conteneur applicatif mais il peut en être composé plusieurs. |
| Il répondrait | L’équilibrage de charge | ✅ | Un ReplicaSet assure le suivi et maintient le nombre d’instances attendues et en cours d’exécution pour un pod donné. |
| Déploiement | – | ✅ | Un déploiement assure le suivi et maintient la configuration requise pour un pod et un jeu de réplicas. |
| Ensemble avec état | – | ✅ | Un StatefulSet est un déploiement avec une assurance sur l’ordre de démarrage et une liaison de volume, pour maintenir un état cohérent dans le temps. |
| Nœud | Hôte | ❌ | Un nœud peut être une machine physique ou virtuelle prête à héberger des pods. |
| Service | Réseau | ✅ | Un service définira un point d’entrée vers un ensemble de pods sémantiquement liés entre eux. |
| Entrée | Proxy inverse | ✅ | Une entrée publie des services en dehors du cluster. |
| Grappe | Centre de données | ❌ | Un cluster est l’ensemble des nœuds disponibles, y compris les contrôleurs Kubernetes. |
| Espace de noms | – | ➖ | Un espace de noms définit un pseudo-cluster isolé dans le cluster actuel. |
| Classe de stockage | Disque | ❌ | Une StorageClass configure les sources des systèmes de fichiers qui peuvent être utilisées pour créer dynamiquement des PersistentVolumes. |
| Volume persistant | Partition de disque | ❌ | Un PersistentVolume décrit tout type de système de fichiers prêt à être monté sur un pod. |
| Réclamation de volume persistant | – | ✅ | Un PersistentVolumeClaim lie un PersistentVolume à un pod, qui peut ensuite l’utiliser activement pendant son exécution. |
| Carte de configuration | Variables d’environnement | ✅ | Un ConfigMap définit des propriétés largement accessibles. |
| Secrète | Env. Sécurisé. Var. | ✅ | Un secret définit des propriétés largement accessibles avec des limitations potentielles de cryptage et d’accès. |
Lectures complémentaires :
Fichiers de définition
Les ressources dans Kubernetes sont créées de manière déclarative, et bien qu’il soit possible de configurer le déploiement de votre application via la ligne de commande, une bonne pratique consiste à garder une trace des définitions de ressources dans un environnement versionné. Parfois appelée GitOps , cette pratique n’est pas seulement applicable à Kubernetes mais largement appliquée aux systèmes de livraison, soutenue par le mouvement DevOps .
À cet effet, Kubernetes propose une représentation YAML de la déclaration de ressource, et sa structure peut être résumée comme suit :
| Champ | Type de fichier | Contenu |
|---|---|---|
apiVersion | Tous les fichiers | Version à utiliser lors de l’analyse du fichier. |
kind | Tous les fichiers | Type de ressource décrite par le fichier. |
metadata | Tous les fichiers | Identification et étiquetage des ressources. |
data | Fichiers centrés sur les données (Secret, ConfigMap) | Point d’entrée de contenu pour le mappage des données. |
spec | La plupart des fichiers (Pod, Déploiement, Ingress, …) | Point d’entrée de contenu pour la configuration des ressources. |
Attention : certaines ressources comme StorageClass n’utilisent pas de point d’entrée unique comme décrit ci-dessus
Métadonnées et étiquettes
La saisie des métadonnées est essentielle lors de la création d’une ressource, car elle permettra à Kubernetes et à vous-même d’identifier et de sélectionner facilement la ressource.
Dans cette entrée, vous définirez a nameet a namespace(par défaut default), grâce auxquels le plan de contrôle pourra automatiquement savoir si le fichier est un nouvel ajout au cluster ou la révision d’un fichier précédemment chargé.
En plus de ces éléments, vous pouvez définir une labelssection.
Il est composé d’un ensemble de paires clé-valeur permettant d’affiner le contexte et le contenu de votre ressource. Ces étiquettes peuvent ensuite être utilisées dans presque toutes les commandes CLI via Selectors . Comme ces entrées ne sont pas utilisées dans le comportement principal de Kubernetes, vous pouvez utiliser le nom de votre choix, même si Kubernetes définit certaines recommandations de bonnes pratiques .
Enfin, vous pouvez également créer une annotationssection presque identique à labelsKubernetes, mais pas du tout utilisée par celui-ci. Ceux-ci peuvent être utilisés du côté applicatif pour déclencher des comportements ou simplement ajouter des données pour faciliter le débogage.
# <metadata> narrows down selection and identify the resource
metadata:
# The <name> entry is required and used to identify the resource
name: my-resource
namespace: my-namespace-or-default
# <labels> is optional but often needed for resource selection
labels:
app: application-name
category: back
# <annotations> is optional and not needed for the configuration of Kubernetes
annotations:
version: 4.2
Fichiers de configuration centrés sur les données
Ces fichiers définissent des mappages clé-valeur qui peuvent être utilisés ultérieurement dans d’autres ressources. Habituellement, ces ressources ( c’est-à-dire Secrets et ConfigMap) sont chargées avant toute autre chose, car il est plus probable qu’improbable que vos fichiers d’infrastructure en dépendent.
apiVersion: v1
# <kind> defines the resource described in this file
kind: ConfigMap
metadata:
name: my-config
data:
# <data> configures data to load
configuration_key: "configuration_value"
properties_entry: |
# Any multiline content is accepted
multiline_config=true
Fichiers de configuration centrés sur l’infrastructure
Ces fichiers définissent l’infrastructure à déployer sur le cluster, en utilisant potentiellement le contenu des fichiers de données.
apiVersion: v1
# <kind> defines the resource described in this file
kind: Pod
metadata:
name: my-web-server
spec:
# <spec> is a domain specific description of the resource.
# The specification entries will be very different from one kind to another
Définition des ressources
Dans cette section, nous allons regarder de plus près la configuration des ressources les plus utilisées sur une application Kubernetes. C’est aussi l’occasion de mettre en valeur les interactions entre les ressources.
À la fin de la section, nous aurons un serveur Nginx en cours d’exécution et pourrons contacter le serveur depuis l’extérieur du cluster. Le diagramme suivant résume l’état prévu :

Carte de configuration
ConfigMap est utilisé pour contenir des propriétés qui pourront être utilisées ultérieurement dans vos ressources.
apiVersion: v1
kind: ConfigMap
metadata:
name: simple-web-config
namespace: default
data:
configuration_key: "Configuration value"
La configuration définie ci-dessus peut ensuite être sélectionnée à partir d’une autre définition de ressource avec l’extrait suivant :
valueFrom:
configMapKeyRef:
name: simple-web-config
key: configuration_key
Remarque : les ConfigMaps ne sont disponibles que dans l’espace de noms dans lequel ils sont définis.
Lectures complémentaires :
Secrète
Toutes les données sensibles doivent être placées dans des fichiers secrets (par exemple, clés API, phrases secrètes,…). Par défaut, les données sont simplement conservées sous forme de valeurs codées en base64 sans cryptage. Cependant, Kubernetes propose des moyens d’atténuer les risques de fuite en intégrant un contrôle d’accès basé sur les rôles ou en chiffrant les secrets .
Le fichier Secret définit une typeclé à sa racine, qui peut être utilisée pour ajouter une validation sur les clés déclarées dans l’ dataentrée. Par défaut, le type est défini sur Opaquece qui ne valide pas du tout les entrées.
apiVersion: v1
kind: Secret
metadata:
name: simple-web-secrets
# Opaque <type> can hold generic secrets, so no validation will be done.
type: Opaque
data:
# Secrets should be encoded in base64
secret_configuration_key: "c2VjcmV0IHZhbHVl"
Le secret défini ci-dessus peut ensuite être sélectionné dans une autre définition de ressource avec l’extrait suivant :
valueFrom:
secretKeyRef:
name: simple-web-secrets
key: secret_configuration_key
Remarque : Les secrets sont uniquement disponibles dans l’espace de noms dans lequel ils sont définis.
Sous
Un fichier de définition de pod est assez simple mais peut devenir assez volumineux en raison de la quantité de configuration disponible. Les champs nameet imagesont les seuls obligatoires, mais vous pouvez couramment utiliser :
portspour définir les ports à ouvrir à la fois sur le conteneur et le pod.envpour définir les variables d’environnement à charger sur le conteneur.argsetentrypointpour personnaliser la séquence de démarrage du conteneur.
Les pods ne sont généralement pas créés en tant que ressources autonomes sur Kubernetes, car les meilleures pratiques indiquent d’ utiliser les pods dans le cadre d’une définition de niveau supérieur ( par exemple, le déploiement). Dans ces cas, le contenu du fichier Pod sera simplement intégré dans le fichier de l’autre ressource.
apiVersion: v1
kind: Pod
metadata:
name: my-web-server
spec:
# <containers> is a list of container definition to embed in the pod
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
env:
- name: SOME_CONFIG
# Create a line "value: <config_entry>" from the ConfigMap data
valueFrom:
configMapKeyRef:
name: simple-web-config
key: configuration_key
- name: SOME_SECRET
# Create a line "value: <config_entry>" from the Secret data
valueFrom:
secretKeyRef:
name: simple-web-secrets
key: secret_configuration_key
Remarque : Les pods ne sont disponibles que dans l’espace de noms dans lequel ils sont définis.
Déploiement
Le déploiement est généralement utilisé comme unité de travail atomique car il va automatiquement :
- Créez une définition de pod basée sur l’
templateentrée. - Créez un ReplicaSet sur les pods sélectionnés par l’
selectorentrée, avec la valeur dereplicasen nombre de pods qui doivent être exécutés.
Le fichier suivant demande 3 instances d’un serveur Nginx exécuté à tout moment. Le fichier peut paraître un peu lourd, mais il s’agit en grande partie de la définition du Pod copiée ci-dessus.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-web-server-deployment
namespace: default
labels:
app: webserver
spec:
# <selector> should retrieve the Pod defined below, and possibly more
selector:
matchLabels:
app: webserver
instance: nginx-ws-deployment
# <replicas> asks for 3 pods running in parallel at all time
replicas: 3
# The content of <template> is a Pod definition file, without <apiVersion> nor <kind>
template:
metadata:
name: my-web-server
namespace: default
labels:
app: webserver
instance: nginx-ws-deployment
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
env:
- name: SOME_CONFIG
# Create a line "value: <config_entry>" from the ConfigMap data
valueFrom:
configMapKeyRef:
name: simple-web-config
key: configuration_key
- name: SOME_SECRET
# Create a line "value: <config_entry>" from the Secret data
valueFrom:
secretKeyRef:
name: simple-web-secrets
key: secret_configuration_key
Remarque : Les déploiements ne sont disponibles que dans l’espace de noms dans lequel ils sont définis.
Service
Un pod peut être supprimé et recréé à tout moment. Lorsque cela se produit, l’adresse IP du pod change, ce qui peut entraîner une perte de connexion si vous le contactez directement. Pour résoudre ce problème, un Service fournit un point de contact stable à un ensemble de Pods, tout en restant indépendant de leur état et de leur configuration. Habituellement, les Pods sont choisis pour faire partie d’un Service via une selectorentrée, donc en fonction de son labels. Un Pod est sélectionné si et seulement si toutes les étiquettes du sélecteur sont portées par le pod.
Il existe trois types de services qui agissent de manière très différente, parmi lesquels vous pouvez sélectionner à l’aide de la saisie de type.
Le service ClusterIP est lié à une adresse IP interne du cluster, donc uniquement accessible en interne. Il s’agit du type de service créé par défaut et convient pour lier différentes applications au sein du même cluster.
Un service NodePort liera un port (par défaut dans la plage 30 000 à 32 767) sur les nœuds hébergeant les pods sélectionnés. Cela vous permet de contacter le service directement via l’adresse IP du nœud. Cela signifie également que votre service sera aussi accessible que les machines virtuelles ou physiques hébergeant ces pods.
Remarque : L’utilisation de NodePort peut présenter des risques de sécurité, car elle permet une connexion directe depuis l’extérieur du cluster.
Un service LoadBalancer créera automatiquement une instance d’équilibrage de charge à partir du fournisseur de services cloud sur lequel le cluster est exécuté. Cet équilibreur de charge est créé en dehors du cluster mais sera automatiquement lié aux nœuds hébergeant les pods sélectionnés.
Il s’agit d’un moyen simple d’exposer votre service, mais qui peut s’avérer coûteux car chaque service sera géré par un seul équilibreur de charge.
Si vous configurez votre propre Ingress comme nous le ferons ici, vous souhaiterez peut-être utiliser un ClusterIpservice, car d’autres services sont conçus pour des cas d’utilisation spécifiques.
apiVersion: v1
kind: Service
metadata:
name: simple-web-service-clusterip
spec:
# ClusterIP is the default service <type>
type: ClusterIP
# Select all pods declaring a <label> entry "app: webserver"
selector:
app: webserver
ports:
- name: http
protocol: TCP
# <port> is the port to bind on the service side
port: 80
# <targetPort> is the port to bind on the Pod side
targetPort: 80
Remarque : Les services sont définis dans un espace de noms mais peuvent être contactés à partir d’autres espaces de noms.
Entrée
Ingress vous permet de publier des services internes sans nécessairement utiliser un équilibreur de charge des fournisseurs de services cloud. Vous n’avez généralement besoin que d’une seule entrée par espace de noms, où vous pouvez lier autant de routages rulesque backendsvous le souhaitez. Un backend sera généralement un ClusterIPservice routé en interne.
Veuillez noter que Kubernetes ne gère pas lui-même les ressources d’entrée et s’appuie sur des implémentations tierces. Par conséquent, vous devrez choisir et installer un contrôleur d’entrée avant d’utiliser une ressource d’entrée. D’un autre côté, cela rend la ressource d’entrée personnalisable en fonction des besoins de votre cluster.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: simple-web-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
# Using <host> redirects all request matching the given DNS name to this rule
- host: "*.minikube.internal"
http:
paths:
- path: /welcome
pathType: Prefix
backend:
service:
name: simple-web-service-clusterip
port:
number: 80
# All other requests will be redirected through this rule
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: simple-web-service-clusterip
port:
number: 80
Remarque : Les entrées sont définies dans l’espace de noms mais peuvent contacter des services d’autres espaces de noms et sont accessibles publiquement en dehors du cluster.
Utilisation de la CLI
Créer et gérer des ressources
Cette section présente les commandes CLI de base pour manipuler les ressources. Comme indiqué précédemment, bien qu’il soit possible de gérer manuellement les ressources, une meilleure pratique consiste à utiliser des fichiers.
# <kind> is the type of resource to create (e.g. deployment, secret, namespace, quota, ...)
$ kubectl create <kind> <name>
$ kubectl edit <kind> <name>
$ kubectl delete <kind> <name>
# All those commands can be used through a description file.
$ kubectl create -f <resource>.yaml
$ kubectl edit -f <resource>.yaml
$ kubectl delete -f <resource>.yaml
Pour faciliter les manipulations de ressources via les fichiers, vous pouvez réduire les interactions avec la CLI aux deux commandes suivantes :
# Create and update any resource
$ kubectl apply -f <resource>.yaml
# Delete any resource
$ kubectl delete -f <resource>.yaml
Lectures complémentaires :
Surveiller et déboguer
Récupérer des ressources
Vous pouvez voir toutes les ressources exécutées via la CLI à l’aide de kubectl get <kind>. Cette commande est assez puissante et vous permet de filtrer le type de ressources à afficher ou de sélectionner les ressources que vous souhaitez voir.
Remarque : s’il n’est pas spécifié, Kubernetes fonctionnera sur l’ defaultespace de noms. Vous pouvez spécifier -n <namespace>de travailler sur un espace de noms spécifique ou -Ad’afficher chaque espace de noms.
# Fetch everything
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/my-web-server-deployment-58c4fd887f-5vm2b 1/1 Running 0 128m
pod/my-web-server-deployment-58c4fd887f-gq6lr 1/1 Running 0 128m
pod/my-web-server-deployment-58c4fd887f-gs6qb 1/1 Running 0 128m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/simple-web-service-clusterip ClusterIP 10.96.96.241 <none> 80/TCP,443/TCP 60m
service/simple-web-service-lb LoadBalancer 10.108.182.232 <pending> 80:31095/TCP,443:31940/TCP 60m
service/simple-web-service-np NodePort 10.101.77.203 <none> 80:31899/TCP,443:31522/TCP 60m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/my-web-server-deployment 3/3 3 3 136m
NAME DESIRED CURRENT READY AGE
replicaset.apps/my-web-server-deployment-58c4fd887f 3 3 3 128m
# We can ask for more details
$ kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
my-web-server-deployment 3/3 3 3 121m web nginx app=webserver
# Some resources are not visible using "all" but available
$ kubectl get configmap
NAME DATA AGE
kube-root-ca.crt 1 38d
simple-web-config 3 3h17m
Creusez dans une ressource particulière
Cette section vous montrera comment accéder aux ressources. La plupart des opérations quotidiennes requises sont réalisables via les trois commandes suivantes.
La première commande vous donnera la configuration complète de la ressource, en utilisant kubectl describe <kind>/<name>.
# Let's describe the ingress for the sake of example
$ kubectl describe ingress/simple-web-ingress
Name: simple-web-ingress
Namespace: default
Address: 192.168.64.2
Default backend: default-http-backend:80 (<error: endpoints "default-http-backend" not found>)
Rules:
Host Path Backends
---- ---- --------
*.minikube.internal
/welcome simple-web-service-clusterip:80 (172.17.0.4:80,172.17.0.5:80,172.17.0.6:80 + 1 more...)
*
/ simple-web-service-clusterip:80 (172.17.0.4:80,172.17.0.5:80,172.17.0.6:80 + 1 more...)
Annotations: nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal UPDATE 7m6s (x6 over 23h) nginx-ingress-controller Ingress default/simple-web-ingress
Une autre commande importante est kubectl logs <kind>/<name>, comme vous pouvez vous y attendre, elle vous montre les journaux des ressources, le cas échéant. Comme les journaux sont produits par les pods, l’exécution d’une telle commande sur une ressource au-dessus d’un pod fouillera Kubernetes pour afficher les journaux d’un pod choisi au hasard en dessous.
$ kubectl logs deployments/my-web-server-deployment
Found 3 pods, using pod/my-web-server-deployment-755b499f77-4n5vn
# [logs]
Enfin, il est parfois utile de se connecter sur un pod, vous pouvez le faire avec la commande kubectl exec -it <pod_name> -- /bin/bash. Cela ouvrira un shell interactif sur le pod, vous permettant d’interagir avec son contenu.
# As for logs, when called on any resource enclosing Pods,
# Kubernetes will randomly chose one to execute the action
$ kubectl exec -it deployment/my-web-server-deployment -- /bin/bash
root@my-web-server-deployment-56c4554cf9-qwtm6:/# ls
# [...]
Conclusion
Au cours de cet article, nous avons vu les principes fondamentaux du déploiement et de la publication de services sans état à l’aide de Kubernetes. Mais vous pouvez faire des choses bien plus complexes avec Kubernetes.